Ha! Endlich kommt da mal Bewegung in diese völlig vergurkte #LSR-Sache: google-produkte.blogspot.de/2014/10/news-z… #Google #VGMedia #
Schlagwort: Google
Kategorien
Meine Bilder, meine Besucher
Google hat’s echt im Gespür, wie man sich in die Nesseln setzt. Eine neue Version der Bildersuche ist angekündigt, die laut Google „faster, more reliable“ ist und „lets the images do the talking“. Für die US-Nutzer ist das schon freigeschaltet und über google.com auch aus Deutschland schon benutzbar, drum wollen wir uns das doch mal ansehen.
Zum Vergleich erstmal eine Ergebnisseite der bisherigen Bildersuche nach „Pitigliano“, von dem ich mal ein ganz brauchbares Bild gemacht zu haben scheine:
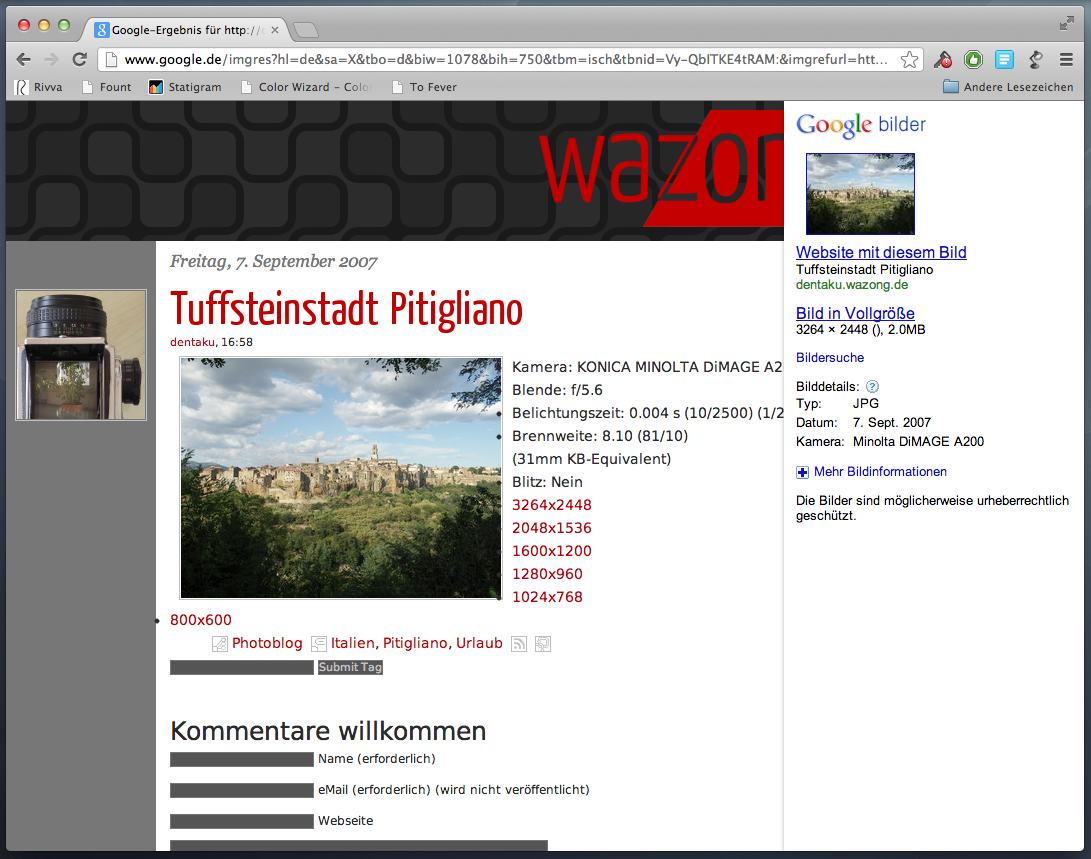
Jetzt das gleiche mit der neuen Suchfunktion:
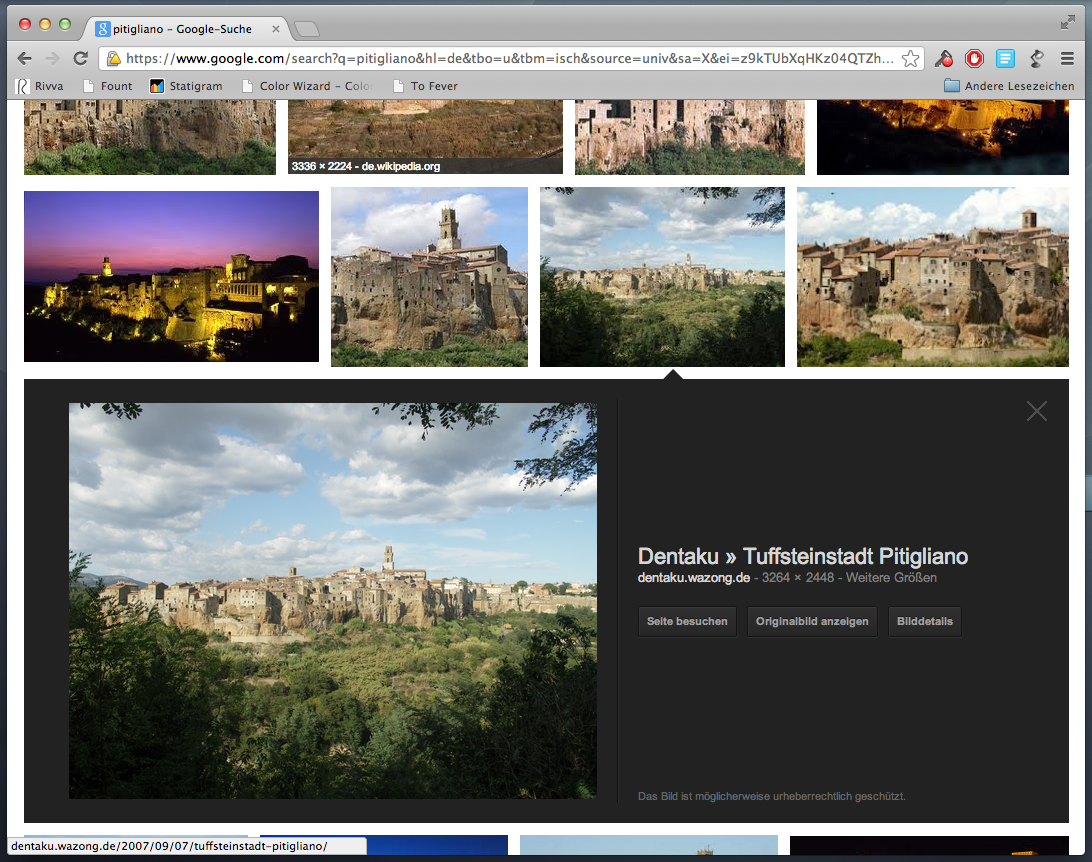
Die umgebende Webseite wird nicht mehr automatisch aufgerufen, stattdessen erscheint eine Fläche mit einem größeren Vorschaubild und den folgenden Wahlmöglichkeiten:
- Seite besuchen (führt zur Seite)
- Originalbild anzeigen (führt direkt zum Bild)
- Bilddetails (führt zu einer Ähnlichkeitssuche mit dem Bild als Ausgangsbild)
{kind=link}
Ein Untertitel warnt: „Das Bild ist möglicherweise urheberrechtlich geschützt.“, trotzdem kann der Benutzer das Bild sofort in voller Auflösung herunterladen, ohne mit eventuell auf der Seite vorhandenen Hinweisen zur Verwendung behelligt zu werden. Um das klarzustellen: Google klaut die Bilder nicht (und „klauen“ ist natürlich ohnehin die falsche Metapher) sondern verlinkt auf die Originaldatei auf dem Originalserver — aber auf eine Weise, die den Besucher nicht mehr auf die Seite lenkt, und ihn damit auch nicht in den heute üblichen Statistiktools auftauchen lässt (wer will schon zurück zu webalizer).
Aus Nutzersicht spricht natürlich einiges für die neue Implementation: wie oft ist es z.B. schon passiert, dass ich auf die Seite kam, auf der das Bild angeblich sein sollte, und es war nirgendwo zu sehen (z.B. weil Google das Bild auf Seite 7 eines Blogs oder Forums gefunden hatte, und es sich inzwischen auf Seite 9 befand)?
Aber Google tut hier genau das, was die Zeitschriftenverleger ihnen als Begründung für das unselige Leistungsschutzrecht ununterbrochen vorwerfen: sie binden urheberrechtlich geschützte Werke anderer auf der eigenen Seite ein, ohne dabei auf eventuelle Lizenzregelungen zu achten. Die Anzeige der verkleinerten Vorschaubilder in den Suchergebnissen der Bildersuche ist Google ohne besondere Genehmigung gestattet, und möglicherweise deckt das entsprechende BGH-Urteil auch diese neue Variante ab, aber wie auch schon bei Stefan Niggemeier zu lesen war ist die Änderung gerade in der aktuellen Lage der Diskussion zumindest extrem ungeschickt.
Unter „Verteidige Dein Bild“ hat sich jetzt eine Online-Petition (Ok, etwas wirkungsloseres gibt es kaum, aber es geht um den symbolischen Wert) gegen die neue Bildersuche formiert, die ich auch mitunterzeichnet habe. Und wenn das auch nichts hilft, dann muss ich eben wieder die Maßnahmen von damals rauskramen.
Kategorien
Wo wir gerade live dabei sind:…
Wo wir gerade live dabei sind: man kann sich seine Mitstreiter eben nicht aussuchen dentaku.wazong.de/2012/11/29/t…hutzrecht/ #LSR #Google #
Kategorien
Trotzdem noch doof: Leistungsschutzrecht
Keine Angst, es folgt nicht noch ein Text darüber, dass robots.txt eigentlich schon helfen würde oder ähnliches. Das steht ja schon überall.
Google hat eine Kampagne gestartet. Es erklärt seinen Benutzern, dass das gerade geplante Leistungsschutzrecht für Presseverlage (im folgenden Text immer mit LSR abgekürzt) die Funktion der Suchmaschine und damit die Nützlichkeit des ganzen Internets bedrohe. Das ist natürlich übertrieben, aber in der Tat richtet sich das LSR hauptsächlich gegen Google.
Das Entsetzen in den Artikeln auf den Zeitungswebseiten ist entsprechend groß. Wie kann sich Google nur das Recht herausnehmen, seine „Monopolstellung“ für PR in eigener Sache zu nutzen? Nun, natürlich hat Google dasselbe Recht, die große Aufmerksamkeit, die es durch seine Marktmacht erhält, für die Verbreitung seiner Anliegen zu nutzen, wie es die Content-Allianz-Mitglieder z.B. in der FAZ und der Tagesschau hat (zusammen haben die wahrscheinlich sogar eine größere Reichweite).
Auch wenn die Presse gern den Gegensatz zwischen „Datenkrake Google“ und sich selbst als „Verteidiger der Demokratie“ ins Feld führt, gibt es keinen Grund, hier mit zweierlei Maß zu messen. Wir sollen nämlich glauben, Zeitungsverlage und Suchmaschinen wären in verschiedenen Branchen beheimatet, aber das stimmt gar nicht: sobald die Zeitung nicht mehr auf Papier gedruckt ist, lebt sie ausschließlich von der auf der Seite geschalteten Werbung — und bei Suchmaschinen gab es AFAIK noch nie eine andere Finanzierung. Es handelt sich bei Google und den Verlagen heutzutage also um direkte Konkurrenten in der Vermietung meiner Bildschirmfläche an Werbekunden. Da möchte man doch ungern zwischen die Fronten geraten.
Das LSR birgt aber trotzdem mögliche Fallen und Rechtsunsicherheiten auch für uns einfache Ins-Internet-Schreiber. Nach aktuell vorherrschender Auslegung sollten alle normalen Blogartikel — auch mit Zitaten und Links — unproblematisch sein, aber Formulierungen wie:
Zulässig ist die öffentliche Zugänglichmachung von Presseerzeugnissen oder Teilen hiervon, soweit sie nicht durch gewerbliche Anbieter von Suchmaschinen oder gewerbliche Anbieter von Diensten erfolgt, die Inhalte entsprechend aufbereiten.
Im Übrigen gelten die Vorschriften des Teils 1 Abschnitt 6 entsprechend.
(aus dem Entwurf, Hervorhebung von mir) könnte man zum Beispiel auch problemlos auf die beliebten Linklistenartikel und Dienste wie Rivva und quote.fm beziehen. Solche Unsicherheiten sind schon Grund genug, gegen das LSR zu sein. Das wird nicht gerade einfacher, wo jetzt allen Gegnern des LSR unterstellt werden kann, sie seien ohnehin nur von Google bezahlt. Aber man kann sich seine Mitstreiter eben nicht aussuchen (und wann bin ich schon derselben Meinung wie die Junge Union?).
Kategorien
Ääääähm, nein. #Google #V…
Ääääähm, nein. #Google #Vorschlag twitpic.com/b50fco #
Plakatwerbung für Google Chrome http://flic.kr/p/98sxhP #
Ich habe den Widerspruch-Widerspruch nach Sascha Lobo jetzt abgeschickt:
Date: Wed, 11 Aug 2010 13:28:16 +0200
From: Thomas Renger <dentaku@wazong.de>
Subject: Widerspruch gegen einen Widerspruch gegen Google Street View
To: streetview-deutschland@google.com
X-Mailer: Apple Mail (2.1081)Sehr geehrte Damen und Herren,
ich habe Grund zur Annahme, dass Dritte einen Widerspruch gegen die Veröffentlichung des von mir bewohnten Hauses durch den Internetdienst Google Street View eingelegt haben.
Deshalb widerspreche ich hiermit einem eventuellen Widerspruch der Speicherung und Veröffentlichung von Abbildungen des von mir bewohnten Hauses durch den Internetdienst Google Street View. Ich möchte, dass meine Hausfassade als Teil der Digitalen Öffentlichkeit voll streetviewbar ist.
Es handelt sich um die Liegenschaft:
Bebelstraße 36 in 70193 StuttgartNähere Beschreibung des Objektes:
Das 1896 in Ziegelbauweise mit Sandsteinfronten (zu den angrenzenden Straßen hin) errichtete Mehrfamilienhaus ist in seiner Bauweise typisch für das Stadtviertel. Im Erdgeschoss befindet sich eine öffentliche Gaststätte.Diese Daten dürfen nur zur Bearbeitung des Widerspruchs gegen einen eventuellen Widerspruch verwendet werden. Einer Nutzung oder Verarbeitung zu anderen Zwecken oder durch Dritte widerspreche ich ausdrücklich.
Um die Bestätigung des Eingangs und Berücksichtigung meines Widerspruchs wird gebeten.
Mit freundlichen Grüßen
—
thomas renger
dentaku@wazong.de
Google hat sofort automatisch geantwortet:
[…] Wir bestätigen den Eingang Ihres Widerspruches in Bezug auf Google Maps StreetView. […]
Ich hoffe, die lesen das nochmal ordentlich durch…
Kategorien
Dieser Buzz von nebenan (webciety)
Dieser Buzz von nebenan (webciety)
[…] Direkt neben Twitter ist diese komische WG, ein Kommen und Gehen, kaum auszuhalten. Gemietet hatte die Wohnung damals wohl dieser seltsame identi.ca (wo der wohl heute ist?), mit dem kam man ja kaum ins Gespräch. Inzwischen scheinen hauptsächlich Foursquare und Gowalla drin zu wohnen, die sich dauernd streiten, was jetzt wo liegt und wer das dort hingelegt hat. Ein paar Bekannte von ihnen schlafen ebenso regelmässig wie unauffällig ein paar Tage auf dem Sofa, nur um wenig später genauso unauffällig wieder auszuziehen. […]
Gnihihihi.
aus Delicious/steinhobelgruen
Google-Bashing: Zur politischen Ökonomie einer Suchmaschine
Gute Zusammenfassung auf CARTA.
aus Delicious/steinhobelgruen
Kategorien
@jowe Hmmm, verstehe schon pip…
Kategorien
Google, 1968 – Spreeblick
Google, 1968 – Spreeblick
G O O G L E
__Web __Images __Groups __News __Froogle
Please print query clearly: _______________________
Mail to: Google Search Request
1600 Amphitheatre Parkway
Mountain View, CA 94043
Please allow four to six weeks for results
aus Delicious/steinhobelgruen
M.C. Escher arbeitet für Google Maps | Spreeblick
Mir ist schlecht…
aus Delicious/steinhobelgruen
Kategorien
Da! Da! Schon wieder!
Google macht jetzt auch genau das, was ich gestern bemängelt habe. Das fällt aber auch den Kommentatoren bei Google auf. z.B.:
This is great news – congratulations and many thanks to the Google team working on this project.
Just like to point out though – OpenID is absolutely useless if each site just works as an authentication server but doesn’t accept logins from other OpenID providers….. we’re back where we started with a million different logins for a million different sites unless someone bites the bullet and lets users log in with accounts initially registered on a different OpenID server!
Google, the ball is squarely in your field!
Vielleicht liest das ja bei Google irgendwer…
Wir sind BILD: The Chrome Conspiracy (Spreeblick)
Sobald wir uns im Netz bewegen, geben wir Daten preis. Und erhalten dafür eine ganze Menge: Kostenlose Software und Services, freien Online-Speicherplatz, einfachste Einkaufs-, Kommunikations-, Arbeits- und Handelsmöglichkeiten. Kurz: das Netz.
Delicious/steinhobelgruen
Kategorien
Gefälschter GoogleBot auf der 64.20.43.134
Es sieht ganz so aus als hätte ich Google zu unrecht beschimpft: Bei genauerer Betrachtung stellte ich fest, daß alle unsinnigen GoogleBot-Anfragen von derselben IP-Adresse kamen. Im Gegensatz zu den normalen GoogleBot-Adressen, die alle schön den Eigentümer ausweisen:
dentaku@charon:~$ host 66.249.65.110 Name: crawl-66-249-65-110.googlebot.com Address: 66.249.65.110 dentaku@charon:~$ whois 66.249.65.110 OrgName: Google Inc. OrgID: GOGL Address: 1600 Amphitheatre Parkway City: Mountain View StateProv: CA PostalCode: 94043 Country: US [...]
…scheint diese Adresse jemand ganz anderem zu gehören:
dentaku@charon:~$ host 64.20.43.134 64.20.43.134 does not exist, try again dentaku@charon:~$ whois 64.20.43.134 OrgName: Interserver, Inc OrgID: INTER-83 Address: PO Box 244 City: Fort Lee StateProv: NJ PostalCode: 07024 Country: US [...]
Und tatsächlich: wenn man nach dieser Adresse sucht findet man Hinweise, daß sie sich öfter danebenbenimmt — z.B. eine unbegrenzte Sperre in der Wikipedia. Trotz exakt identischen User-Agent-Eintrags gehe ich mal davon aus, daß die Adresse nichts mit Google zu tun hat und sperre sie ebenfalls aus:
root@charon:~$ iptables -I INPUT -s 64.20.43.134 -j DROP
Kategorien
DIE MERCEDES DIE ALTES WAGEN

…krass