RT @nixcraft: Be like bill Via imgur.com/KxTtDbr #Linux #unix #OSX #Vim #Emacs #editorwar #humor #sysadmin https://t.co/8q7tD0cyef #


DynDNS ist eine praktische Sache: der heimischen Internetverbindung wird ein Name zugewiesen, und wenn die IP-Adresse wechselt, dann kann der automatisch aktualisiert werden. Die meisten handelsüblichen Router können das — aber nicht allein, sondern es wird immer ein spezieller DNS-Server benötigt.
Da gab es mit dyndns.org lange Zeit einen gut funktionierenden kostenlosen Dienst, aber der nennt sich inzwischen dyn.com und will verhältnismäßig viel Geld haben (es gibt zwar immernoch eine kostenlose Variante, aber die muss regelmäßig per Klick auf bunt blinkende Mails wieder freigeschaltet werden). Der Wechsel zu irgendeinem der Konkurrenten verbessert die Lage mutmaßlich immer nur vorübergehend. Außerdem möchte zumindest ich meine Infrastruktur so viel wie möglich selbst betreiben.
Die Aufgabe ist also, einen Eintrag im DNS zu ändern. Eigentlich gibt es einen Prima Standard um DNS-Zonen zu aktualisieren, nämlich das Dynamic DNS Update Protocol, wie es in RFC 2136 und RFC 2137 beschrieben ist. Das können die aktuellen DNS-Server ohne zusätzliche Software, und es ist auch schön kryptographisch abgesichert, aber keiner der handelsüblichen Router kann das (diesem Muster werden wir später nochmal begegnen).
Da muss es doch was von GNU geben. Und tatsächlich: genau diese Aufgabe übernimmt GnuDIP. Das wird zwar seit mehr als 10 Jahren nicht mehr weiterentwickelt, funktioniert aber stabil (Ok, die Webseite sieht sehr altbacken aus und möchte gern ein Java-Applet zur Bestimmung der IP-Adresse verwenden — und was ich davon halte ist ja bekannt).
Im Folgenden richten wir unter der Beispieldomain steinhobelgruen.de eine dynamische Domain dyn.steinhobelgruen.de ein.
Als Basis nehmen wir einen Debian GNU/Linux-Server mit bind9 als DNS-Server und MySQL als Datenbakserver und gehen (zumindest für den mittleren Teil) grob nach dieser Anleitung vor. Leider hat Debian das gnudip-Paket irgendwann aus der Distribution entfernt, wir machen also eine richtig klassische /usr/local-Installation.
Wir laden das Paket runter, entpacken es und „installieren“ die Software:
wget http://gnudip2.sourceforge.net/gnudip-www/src/gnudip-2.3.5.tar.gz tar zxvf gnudip-2.3.5.tar.gz mv gnudip-2.3.5/gnudip /usr/local
Dann legen wir die Datenbank an, dazu passen wir in der Datei gnudip-2.3.5/gnudip.mysql eventuell noch Datenbankname und Passwort an und rufen dann MySQL auf:
mysql -uroot -p < gnudip-2.3.5/gnudip.mysql
In der GnuDIP-Konfiguration unter /usr/local/gnudip/etc/gnudip.conf müssen wir dasselbe Datenbankpasswort konfigurieren.
Die mitgelieferten cgi-Skripten konfigurieren wir auf dem Webserver; dazu fügen wir die folgenden Zeilen in der Konfiguration des Webservers ein (eventuell in einem bestimmten Virtual Host):
[...] Alias /gnudip/html/ /usr/local/gnudip/html/ <Location /gnudip/html/> Options Indexes ReadmeName .README HeaderName .HEADER RemoveHandler .pl RemoveType .pl AddType text/plain .pl </Location> ScriptAlias /gnudip/cgi-bin/ /usr/local/gnudip/cgi-bin/
Erstmal richten wir einen Schlüssel für DNS-Updates ein. Dazu brauchen wir das dnssec-keygen-Tool aus dem Debian-Paket dnsutils.
dnssec-keygen -a hmac-sha512 -b 512 -n HOST gnudip
Der Aufruf erzeugt zwei Dateien, die zum Beispiel Kgnudip.+165+23314.key und Kgnudip.+165+23314.private heißen.
Wenn der DNS-Server eine Domain dynamisch aktualisieren soll, dann braucht er ein Verzeichnis, in dem er Schreibrechte hat. Wir legen also eins an:
mkdir /etc/bind/dyndns chown bind:bind /etc/bind/dyndns
In das neue Verzeichnis legen wir eine fast leere DNS-Zonendatei dyn.steinhobelgruen.de:
$ORIGIN dyn.steinhobelgruen.de.
$TTL 86400
@ IN SOA nyx.wazong.de. hostmaster (
0 ; Serial
3600 ; Refresh
1800 ; Retry
604800 ; Expire
600 ) ; Negative Cache TTL
@ IN NS nyx.wazong.de.
@ IN MX 0 nyx.wazong.de.
@ IN A 188.40.53.18
Die neue Zone deligieren wir in der Zone steinhobelgruen.de an unseren Nameserver:
$ORIGIN steinhobelgruen.de. [...] dyn IN NS nyx.wazong.de.
Den vorhin erzeugten Schlüssel aus der …private-Datei kopieren wir folgendermaßen in die named-Konfiguration aufgenommen (in einer neuen Datei /etc/bind/gnudip.key ) …
key gnudip-key {
algorithm hmac-sha512;
// the TSIG key
secret "u+/X3NGp1aQxvJedO/8j2xHDxtNgBaSOMgAYMo/OtpbUJXh02Fwfi8+u+yNq/zkIp36m2vY85pw8pgKMk5XSAw==";
};
… und in der /etc/bind/named.conf.local legen wir die dynamische Zone an und erlauben die Aktualisierung mit dem Schlüssel:
[...]
// include definition of GnuDIP update key
include "/etc/bind/gnudip.key";
// define GnuDIP dynamic DNS zone
zone "dyn.steinhobelgruen.de" in {
type master;
file "/etc/bind/dyndns/dyn.steinhobelgruen.de";
allow-query { any; };
update-policy { grant gnudip-key subdomain dyn.steinhobelgruen.de; };
};
Wenn alles passt können wir Bind neu starten (bzw. die Konfiguration neu laden).
/etc/init.d/bind9 reload
Der Private Schlüssel kommt zur GnuDIP-Installation nach /usr/local/gnudip/etc/ und wird in /usr/local/gnudip/etc/gnudip.conf eingetragen:
[...] nsupdate = -k /usr/local/gnudip/etc/Kgnudip.+165+23314.private [...]
Nach dieser Einrichtung sollten wir direkt auf dem Webinterface einen Admin-Benutzer und die Domain anlegen. Danach können wir weitere Benutzer anlegen oder sogar Selbstregistrierung einschalten.

An dieser Stelle ist GnuDIP jetzt zu sicher um praktisch zu sein: es definiert nämlich ein eigenes Protokoll für die Aktualisierung der Einträge über HTTP, in der das Passwort zusammen mit einem Salt und einem Zeitstempel in einem MD5-Hash und base64-codiert übertragen wird. Genau so sollte so etwas eigentlich auch gemacht werden, aber keiner der handelsüblichen Router kann das.
Grrrrr! Was können die denn überhaupt?
Nun ja, das ist unterschiedlich. Da ich so eine gerade hier habe, werden wir als Beispiel eine Fritz!Box anbinden. Die unterstützt als DynDNS-Anbieter „Benutzerdefiniert“ und kann dann eine selbstgewählte Update-URL eintragen. Was sie dabei übertragen kann steht in dieser Dokumentation bei AVM. Also habe ich in GnuDIP eine zusätzliche und vereinfachte Update-URL eingebaut, die dazu passt.
Um die bei Euch zu installieren, müsst Ihr dieses Archiv mit zwei Dateien herunterladen, sie auspacken und zu Eurer GnuDIP-Installation dazu kopieren.
Damit ergibt sich als neue Update-URL:
https://steinhobelgruen.de/gnudip/cgi-bin/simpleupdt.cgi?user=<username>&pass=<pass>&domn=<domain>&addr=<ipaddr>&reqc=0 (und zwar genau so mit allen Platzhaltern). Die restlichen Parameter werden wie gewohnt konfiguriert (Achtung! Die Domain muss mit dem Benutzernamen anfangen!)
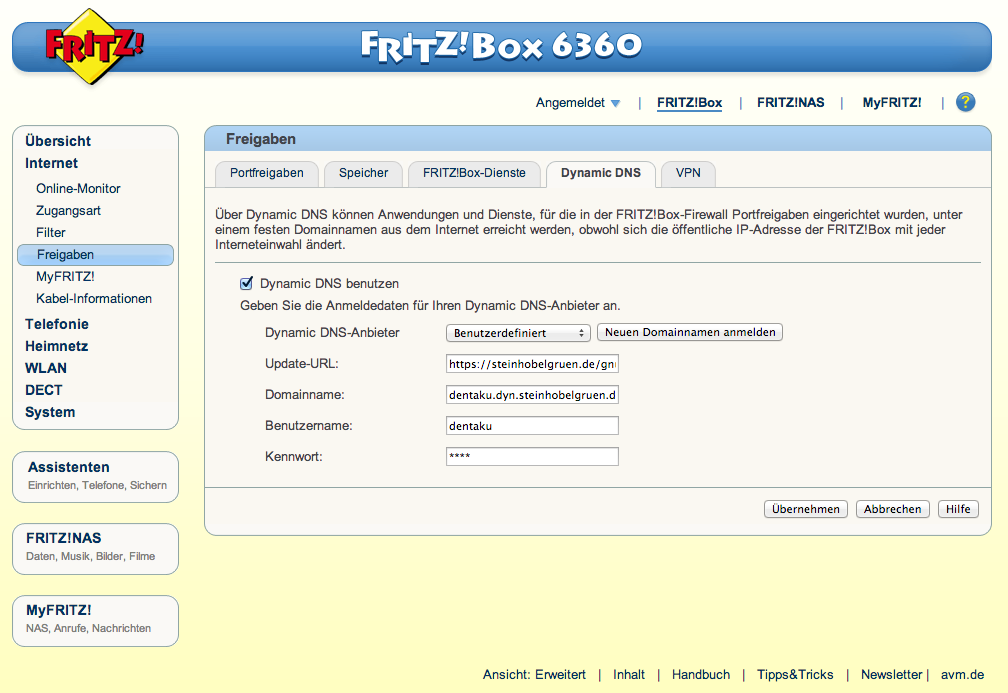
Durch die Änderung werden jetzt Benutzername und Passwort im Klartext über’s Netz geschickt. Das gleiche Problem hat aber auch die Benutzeroberfläche, so dass auf dem Server vielleicht sowieso besser TLS (https) benutzt werden sollte.
Und siehe da: es funktioniert:
dentaku@nyx:~$ host dentaku.dyn.steinhobelgruen.de dentaku.dyn.steinhobelgruen.de has address 78.42.203.144 dentaku@nyx:~$
(P.S.: gebt Euch keine Mühe, die Beispieldomain gibt es wirklich, aber die Schlüssel hier im Blogbeitrag sind natürlich nicht die echten — ach ja, und alle Domain- und Hostnamen werden bei Euch andere sein, wenn Ihr der Anleitung folgt)
Dieser Artikel gehört zur Serie Mein eigener Server.
In Teil 2 habe ich eigentlich versprochen, mit der Konfiguration zu beginnen. Aber vorher muss ich noch zwei kleine Ausflüge machen:
Wie bereits erwähnt haben wir keine Laufwerksbuchstaben sondern nur Verzeichnisse. Dabei verwenden alle UNIX-Betriebssysteme mehr oder weniger die gleichen Verzeichnisstrukturen. Die wichtigsten will ich hier mal aufzählen:
/etc/
Hier liegen die Konfigurationen. Sowohl die des Systems als auch die der meisten Softwarepakete. Beispiele: die Benutzer des Systems sind in /etc/passwd definiert (aber nicht immer), die Konfiguration des Webservers findet sich unter /etc/apache2/ (natürlich nur, wenn Apache 2 als Webserver benutzt wird), die Startskripten für im Hintergrund laufende Dienste sind in /etc/init.d/.
/var/
Hier legen Programme veränderliche Dateien ab. Und Daten, die nur von Serverprogrammen benutzt werden sollen (z.B. die Dateien einer Webseite) liegen auch oft hier.
/usr/
Die ausführbaren Dateien der Software sind größtenteils in diesem Verzeichnis installiert. Einige Grundsystemfunktionen liegen auch in /bin/ und /lib/.
/usr/local/
Programme aus anderen Quellen als der Distribution, zum Beispiel Selbstkompiliertes können hier installiert werden, damit sie sich nicht mit den original ausgelieferten Dateien in die Quere kommen. Manche Distributionen und einige kommerzielle Unixe verwenden zu diesem Zweck auch /opt/.
/home/
Hier haben die Benutzer ihre Homeverzeichnisse. Dort können sie sowohl ihre eigenen Dateien als auch ihre Dotfiles (die persönlichen Konfigurationen für Programme, die so genannt werden, weil ihre Namen meist mit einem Punkt beginnen) ablegen.
/tmp/
Temporäre Dateien. Auf manchen Systemen wird der Inhalt beim Neustart automatisch gelöscht. Es darf deshalb nicht davon ausgegangen werden, dass hier abgelegte Daten über einen längeren Zeitraum erhalten bleiben.
Einer der größten Vorteile der meisten Linuxdistributionen ist die Softwareinstallation mit einem Paketmanager. Der kennt in der Regel die Abhängigkeit der verschiedenen Softwarepakete voneinander, so dass das System immer in einem funktionierenden Zustand sein sollte. Debian verwendet apt.
Die Konfiguration des Paketmanagers liegt in /etc/apt/. Die wichtigste Datei ist sources.list. Darin stehen die Quellen, aus denen das System Installationspakete beziehen soll. Auf einem von Hetzner installierten Debian Squeeze sieht das im Moment so aus:
############################################################################### # Hetzner mirror # deb http://mirror.hetzner.de/debian/packages squeeze main contrib non-free deb http://mirror.hetzner.de/debian/security squeeze/updates main contrib non-free ############################################################################### # backup mirror # deb http://cdn.debian.net/debian/ squeeze main non-free contrib deb-src http://cdn.debian.net/debian/ squeeze main non-free contrib deb http://security.debian.org/ squeeze/updates main contrib non-free deb-src http://security.debian.org/ squeeze/updates main contrib non-free ## backports deb http://mirror.hetzner.de/debian/backports squeeze-backports main contrib non-free deb http://backports.debian.org/debian-backports squeeze-backports main contrib non-free
Das Werkzeug ermöglicht die folgenden Operationen:
apt-get update
Holt die aktuellen Paketlisten von den in sources.list definierten Quellen.
Beispiel:
root@Debian-60-squeeze-64-minimal ~ # apt-get update Get:1 http://mirror.hetzner.de squeeze Release.gpg [1,672 B] Get:2 http://mirror.hetzner.de squeeze/updates Release.gpg [836 B] Get:3 http://mirror.hetzner.de squeeze-backports Release.gpg [1,571 B] [...] Get:33 http://cdn.debian.net squeeze/main amd64 Packages [8,602 kB] Get:34 http://cdn.debian.net squeeze/non-free amd64 Packages [124 kB] Get:35 http://cdn.debian.net squeeze/contrib amd64 Packages [64.1 kB] Fetched 26.1 MB in 6s (4,006 kB/s) Reading package lists... Done root@Debian-60-squeeze-64-minimal ~ # apt-get dist-upgrade
Bringt alle installierten Pakete auf die neueste Version.
apt-get install
Installiert die angegebenen Pakete und versucht dabei, alle Abhängigkeiten aufzulösen (also alle von den Paketen benötigten Pakete ebenfalls zu installieren und alle in Konflikt stehenden Pakete zu deinstallieren). Stellt dann eventuell in einem textbasierten Menüsystem Fragen zur Konfiguration.
Beispiel:
root@Debian-60-squeeze-64-minimal ~ # apt-get install screen Reading package lists... Done Building dependency tree Reading state information... Done The following NEW packages will be installed: screen 0 upgraded, 1 newly installed, 0 to remove and 16 not upgraded. Need to get 624 kB of archives. After this operation, 975 kB of additional disk space will be used. Get:1 http://mirror.hetzner.de/debian/packages/ squeeze/main screen amd64 4.0.3-14 [624 kB] Fetched 624 kB in 0s (9,321 kB/s) Selecting previously deselected package screen. (Reading database ... 17705 files and directories currently installed.) Unpacking screen (from .../screen_4.0.3-14_amd64.deb) ... Processing triggers for man-db ... Processing triggers for install-info ... Setting up screen (4.0.3-14) ... root@Debian-60-squeeze-64-minimal ~ #
So, dass musstet Ihr unbedingt noch wissen. Aber in der nächsten Folge konfigurieren wir wirklich was.
Dieser Artikel gehört zur Serie Mein eigener Server.
Jetzt habt Ihr Euren Server und sitzt vielleicht zum ersten mal vor Linux. Sehen wir uns also mal gemeinsam an, womit wir es hier zu tun haben. Dies ist ein Unix, eins aus einem langen Stammbaum miteinander verwandter Systeme, zu dem auch der erste Webserver und das iPhone gehören.
Linux selbst ist eigentlich „nur“ eine Neuimplementation des Kernels (also der Gerätetreiber, Netzwerktreiber, Prozessverwaltung und ähnlichem), die Linus Torvalds 1991 begonnen hat, und die seitdem von einer unvorstellbaren Anzahl an Entwicklern ständig weiterentwickelt wurde. Den Rest zum Unix-Erlebnis ergänzen die GNU-Tools, die eigentlich in einem ehrgeizigen Projekt entstanden, das Unix durch ein neues Betriebssystem ersetzen wollte (GNU ist eine rekursive Abkürzung und steht für GNU is not Unix). Während dieses Projekt also seine Tools (Befehle, die wir später noch sehen werden, einen C-Compiler,…) ziemlich weit fertiggestellt hatte, wurde der Betriebssystemkern „Hurd“ nicht fertig. Diese Lücke füllte Linux so gut aus, dass ich bezweifle, dass der Hurd-Kern jemals richtig fertig wird. Aufgrund dieser Geschichte bestehen auch einige Leute darauf, das komplette System für Arbeitsplatzrechner und Server „GNU/Linux“ zu nennen — schließlich besteht es ja nicht nur aus dem Kern (und es gibt tatsächlich jede Menge andere Einsatzmöglichkeiten für Linux ohne die komplette GNU-Umgebung).
Da Linux also nicht von einem einzelnen Hersteller stammt, müssen alle Teile des Systems aus verschiedenen Quellen zusammengestellt und erstmal kompiliert werden. Diese Arbeit übernehmen sogenannte Distributoren, von denen es auch eine unüberschaubare Anzahl für die verschiedensten Einsatzzwecke gibt. Für Server ist Debian GNU/Linux (da! da ist es wieder) gut geeignet, weil die Betreuer dieser Distribution großen Wert auf stabile Programmversionen legen.
Die Unix-Philosophie basiert auf nur wenigen Objekttypen. Der wichtigste davon ist die Datei. In Unix ist praktisch alles eine Datei (sogar die Interaktion mit Geräten wird darüber abgebildet). Dateien sind in einer Baumstruktur hierarchisch in Verzeichnissen angeordnet. Laufwerksbuchstaben wie unter Windows gibt es nicht, alle Dateisysteme hängen in einem gemeinsamen Baum, der Wurzelknoten heißt / und / ist auch der Trenner zwischen den Hierarchieebenen des Baums.
Der zweite wichtige Objekttyp ist der Prozess — also das laufende Programm. Prozesse können weitere Prozesse starten. Sowohl Dateien als auch Prozesse haben einen Besitzer. Die daraus entstehende Rechtestruktur sehen wir uns später noch an.
Ein weiterer wichtiger Teil der Unix-Philosophie lautet „Nur ein Zweck für ein Werkzeug“. Auch das wird erst später Sinn ergeben.
Als Beispiel dafür, wie sich das auf die Architektur auswirkt: auch Ihr redet mit Linux über einen Prozess, die sogenannte Shell. Wie von so vielen anderen Dingen gibt es auch davon mehrere zur Auswahl (niemand hat gesagt, dass es nicht mehrere Werkzeuge für den gleichen Zweck geben soll), aber für uns reicht erstmal die Betrachtung der üblichen Linux-Standardshell bash.
Die Shell liest Eure Eingaben aus einer Pseudodatei („Standard Input“), interpretiert sie als Programmtext und startet weitere Prozesse für Euch. Das klingt jetzt auch erstmal abgehoben, aber auch darauf werden wir später wieder zurückkommen. Die Kommandos, die in der Shell zur Verfügung stehen, sind (praktisch) alle einzelne Programme, die als Dateien an bestimmten Stellen des Dateisystems liegen.
Jetzt sehen wir uns mal die wichtigsten Unix-Kommandos an:
Das allerwichtigste Kommando ist man. Es zeigt die Manual Pages des Systems an. Darin sind die Befehle, Dateiformate und sogar Programmierschnittstellen dokumentiert. Der Stil ist für Anfänger nicht leicht zu verstehen, aber nach einiger Eingewöhnung bieten sie eine wichtige Referenz. Seht Euch zur Einstimmung mal man man an.
Bevor wir uns an die Liste machen noch eine Anmerkung zu Programmoptionen: durch die bereits erwähnte Verzweigung des Unix-Stammbaums haben sich für einige grundlegende Kommandos zwei Sätze von gängigen Optionen herausgebildet. Die meisten Linux-Distributionen sind im Laufe ihrer Entwicklung zwischen den beiden größten Lagern („BSD“ und „System V“) gependelt, und so beherrschen die mit Linux gelieferten Varianten oft beide Sätze. Die aus der BSD-Ecke stammenden werden dabei häufig ohne, die aus der System-V-Ecke stammenden mit vorangestelltem – angegeben. Weil das noch nicht verwirrend genug war, hat das GNU-Projekt dann noch einen dritten Satz Optionen mit langen Namen und — (also zwei Strichen) eingeführt.
Da wie gesagt alles im Verzeichnisbaum liegt, müssen wir uns durch den bewegen können. Jeder Prozess hat immer ein Arbeitsverzeichnis. Das gerade aktuelle Arbeitsverzeichnis gibt pwd (print working directory) aus. Mit cd [Verzeichnisname] (change directory) können wir in ein tieferes, mit cd .. wieder eine Ebene nach oben gehen. cd ohne Argumente wechselt in Deine digitale Heimat, das sogenannte Homeverzeichnis.
Übung:
root@Debian-60-squeeze-64-minimal ~ # pwd /root root@Debian-60-squeeze-64-minimal ~ # cd .. root@Debian-60-squeeze-64-minimal / # cd root root@Debian-60-squeeze-64-minimal ~ #
Um zu erfahren, was denn im aktuellen Verzeichnis so rumliegt (und wohin wir überhaupt wechseln könnten) gibt es das Kommando ls, mit der Option -l generiert es seine Liste mit ausführlichen Zusatzinformationen.
Übung:
root@Debian-60-squeeze-64-minimal /tmp # ls a.txt b c root@Debian-60-squeeze-64-minimal /tmp # ls -l total 4.0K -rw-r--r-- 1 root root 0 Apr 18 22:11 a.txt -rw-r--r-- 1 root root 0 Apr 18 22:11 b drwxr-xr-x 2 root root 4.0K Apr 18 22:11 c root@Debian-60-squeeze-64-minimal /tmp #
Die Spalten des langen Listings müssen wir uns jetzt mal ansehen. Von Links nach rechts: Berechtigungen, Linkzahl, Benutzer, Gruppe, Größe, Datum, Name. Die erklärungsbedürftigen Felder im Einzelnen:
Dateien gehören immer einem Benutzer und einer Gruppe. Es ist nicht erforderlich, dass der Benutzer, dem eine Datei gehört, Mitglied der Gruppe ist, der die Datei gehört.
Benutzer und Gruppe bilden die Basis für ein einfaches aber effektives Berechtigungskonzept. Jeweils für den Eigentümer, die Gruppe und den Rest der Welt lassen sich die drei Operationen „lesen“ (r), „schreiben“ (w) und „ausführen“ (x, diese Dateien können als „Programme“ benutzt werden) bzw. „betreten“ (auch x, für Verzeichnisse) erlauben oder verbieten:
-rwxrwxrwx
^^^^^^^^^^
|||||||||| Rechte für alle Benutzer ("Welt"):
|||||||||+--- ausführen / betreten
||||||||+---- schreiben
|||||||+----- lesen
||||||| Rechte für die Gruppe:
||||||+------ ausführen / betreten
|||||+------- schreiben
||||+-------- lesen
|||| Rechte für den Eigentümer:
|||+--------- ausführen / betreten
||+---------- schreiben
|+----------- lesen
+---------- Typmarkierung:
- = normale Datei, d = Verzeichnis, l = Link
Das werden wir später noch öfter in der praktischen Anwendung sehen.
Eine Datei kann in Unix an mehreren Stellen im Verzeichnisbaum eingehängt sein (bitte versucht nicht, Euch das bildlich vorzustellen). Die werden hier gezählt. Erst, wenn die Datei nirgendwo mehr referenziert wird (der Linkcounter also 0 ist), verschwindet sie von der Festplatte. In der täglichen Benutzung könnt Ihr das fast immer ignorieren.
Um den Inhalt einer Textdatei anzuzeigen können wir less benutzen (scrollen mit den Cursortasten, verlassen mit q), zur Bearbeitung gibt es einen bunten Strauß an Editoren (Vorsicht! Die dazugehörigen Religionskriege sind schlimmer als jede Windows-oder-Mac-Diskussion.), von denen ich zum Einstieg nano empfehle, weil der die gerade möglichen Befehle immer anzeigt. Mit rm werden wir unliebsame Dateien wieder los.
Übung:
root@Debian-60-squeeze-64-minimal ~ # less test.txt Hallo Wult! root@Debian-60-squeeze-64-minimal ~ # nano test.txt
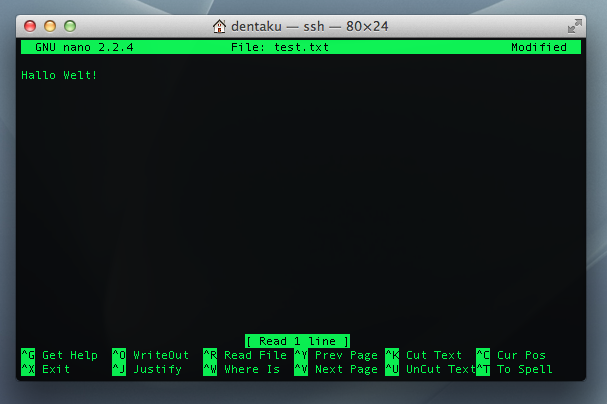
root@Debian-60-squeeze-64-minimal ~ # less test.txt Hallo Welt! root@Debian-60-squeeze-64-minimal ~ # rm test.txt root@Debian-60-squeeze-64-minimal ~ #
ps zeigt die gerade laufenden Prozesse an, ps x nimmt in die Liste auch die Prozesse auf, die gerade nicht mit einem Terminal verbunden sind (hier haben wir jetzt ein Programm, das aus historischen Gründen mit BSD-Style-Optionen gestartet wird). Die erste Spalte dieser Liste ist die Prozess-Id. Wenn wir später mit kill Prozesse abschießen werden, dann brauchen wir die.
Übung:
root@Debian-60-squeeze-64-minimal ~ # ps PID TTY TIME CMD 3067 pts/0 00:00:00 bash 3102 pts/0 00:00:00 ps root@Debian-60-squeeze-64-minimal ~ #
So, das war jetzt eine grobe Übersicht über das Wichtigste — aber alles noch sehr theoretisch. Auf vieles müssen wir deshalb später noch einmal vertiefend in der praktischen Anwendung zurückkommen. In der nächsten Folge reden wir über Netzwerke und fangen tatsächlich mal mit der Serverkonfiguration an.
Dieser Artikel gehört zur Serie Mein eigener Server.
Aus naheliegenden Gründen brauchen wir für die weiteren Kapitel einen Server. Die gibt es bei ganz vielen Hostern und mit sehr unterschiedlichen Leistungsdaten zu sehr unterschiedlichen Preisen zu mieten. Ich gebe hier immer nur Beispiele, Ihr könnt das alles auch anders machen oder woanders Mieten, und das wird dann meistens auch nicht besser oder schlechter sein.
Für unseren Zweck mieten wir mal bei Hetzner einen Virtuellen Server „vServer VQ 12„. Der stellt einen ganz guten Kompromiss aus Kosten und Leistung dar. Der Virtuelle Server ist so etwas wie ein Anteil an einem größeren Server. Wir bekommen 1 GB RAM und 40 GB Plattenplatz zugeteilt, das sollte erstmal reichen.
Für ein großes Blog oder viel Mail oder eine große Menge Dateiablage müssten wir entsprechend höher zielen. Ich persönlich habe z.B. einen „dedizierten“ Server, der einiges mehr leistet und mir allein zur Verfügung steht — benutze den aber auch mit mehreren Leuten und noch einigen Projekten.
Darüberhinaus gibt es noch die sogenannten Managed Server, bei denen der Dienstleister einige der hier beschriebenen Tätigkeiten übernimmt. Das ist aber mit Einschränkungen bei der Softwareinstallation verbunden, und außerdem will er dann auch Geld dafür. Schließlich ist es auch noch möglich, nur Platz in einem Serverschrank zu mieten und dort eigene Hardware hineinzustellen. All das ist nichts für uns.
Als Betriebssystem bestellen wir Debian Linux — Minimal und ohne Plesk, ihr sollt ja schließlich lernen, was da im Hintergrund passiert.
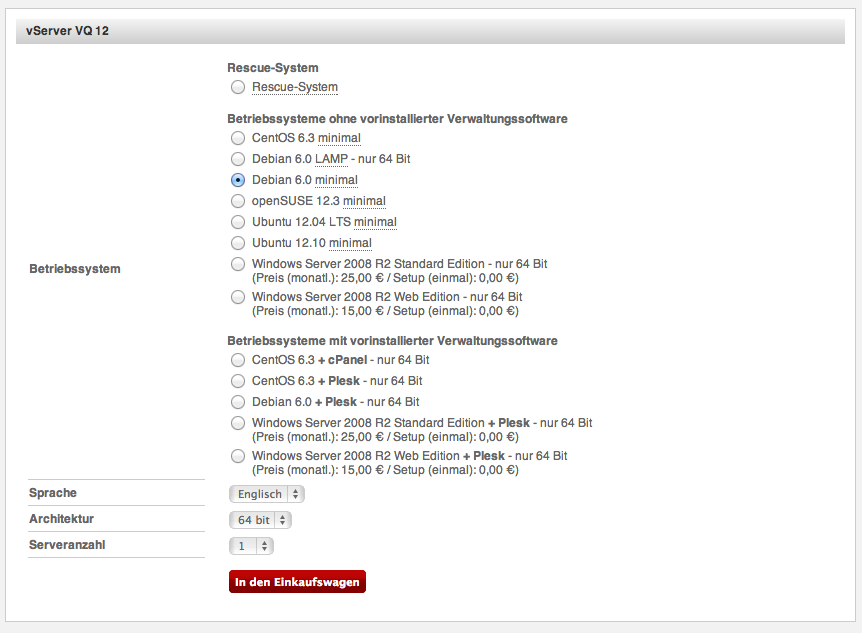
Nach der Bestellung dauert es einige Zeit (bei virtuellen Servern nur wenige Minuten bis Stunden), dann kommt eine Mail:
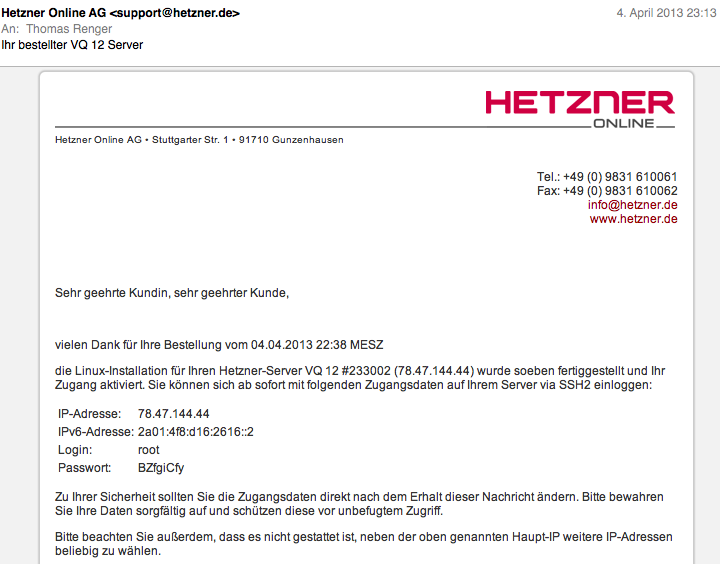
Um jetzt irgendwas mit dem Server machen zu können, brauchen ein Terminalprogramm und einen ssh-Client. ssh ist ein Protokoll, mit dem verschlüsselt Tastatureingaben zum Server hin und die Textausgabe zum Client zurück übertragen werden (mehr dazu später). Das klingt erst einmal nach reinem Befehle tippen, aber schon seit der Zeit der Textterminals gibt es auch ausgeklügelte Benutzerinterfaces, die darauf basieren. Das werden wir später noch sehen.
Die Macuser unter Euch müssen nichts installieren, für die Windowsbenutzer empfehle ich PuTTY.
Log geht’s, wir verbinden uns jetzt zum ersten mal zu unserer nagelneuen Außenstelle: auf dem Mac öffnet das Programm „Terminal“ und gebt ein ssh root@[die Adresse aus der Mail], unter Windows öffnet PuTTY und verbindet Euch zu der Adresse aus der Mail:
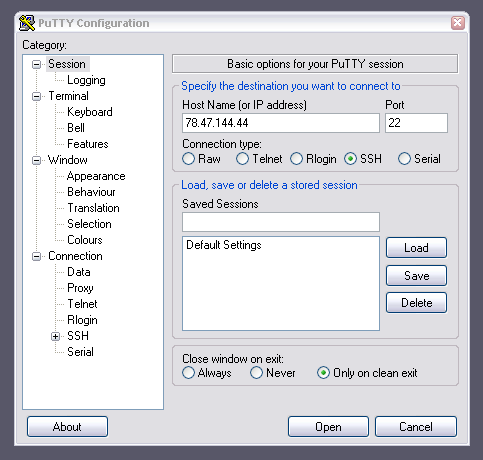
Jeder der ssh-Clients wird beim ersten Kontakt zum neuen Server eine Sicherheitsfrage nach dem „RSA-Fingerabdruck“ stellen. Im Moment haben wir keinen Grund anzunehmen, dass es sich nicht um den richtigen Server handelt, drum sagen wir einfach ja. Es passiert jetzt etwa folgendes (keine Sorge wenn das Passwort beim Tippen nicht zu sehen ist, auch nicht als ******, das gehört so):
Mac:~ dentaku$ ssh root@78.47.144.44 The authenticity of host '78.47.144.44 (78.47.144.44)' can't be established. RSA key fingerprint is 6e:8a:dc:13:63:6c:03:8e:5a:45:cb:3e:13:99:36:f6. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added '78.47.144.44' (RSA) to the list of known hosts. root@78.47.144.44's password: Linux Debian-60-squeeze-64-minimal 2.6.32-5-amd64 #1 SMP Mon Feb 25 00:26:11 UTC 2013 x86_64 The programs included with the Debian GNU/Linux system are free software; the exact distribution terms for each program are described in the individual files in /usr/share/doc/*/copyright. Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent permitted by applicable law. root@Debian-60-squeeze-64-minimal ~ #
So, jetzt seid Ihr auf einem Unix-System. Herzlich Willkommen! Ändert erstmal das Passwort durch Eingeben des Befehls passwd (mit der Return-Taste abschicken und den Anweisungen folgen, es sind wieder keine ****** für das Passwort zu sehen, gewöhnt Euch dran).
root@Debian-60-squeeze-64-minimal ~ # passwd Enter new UNIX password: Retype new UNIX password: passwd: password updated successfully root@Debian-60-squeeze-64-minimal ~ #
Im nächsten Kapitel folgt eine ausführliche Rundtour durch Unix bzw. Linux. Für heute verlassen wir den Server mit dem Befehl exit.
Willkommen bei unserer kleinen Systemadministrationsschulung. Warum machen wir das?
In letzter Zeit erscheinen viele Artikel mit dem Fazit, dass man seine Daten doch besser auf eigener Infrastruktur behalten sollte. Der Anlass ist mal die Abschaltung eines Dienstes mal seltsame Auslegungen der Nutzungsbedingungen und mal die Ankündigung, dass Behörden hier oder anderswo problemlos in die Daten Einsicht nehmen können.
Für uns Softwareentwickler und Systemadministratoren ist das kein Problem, für andere Webbenutzer ungleich schwieriger. Ich hatte deshalb mal versprochen, eine Anleitung zu schreiben
Die im Web zu findenden Tutorials sind meist für Administratoren mit erheblichem Grundwissen geschrieben und erklären selten die Motivation hinter bestimmten Konfigurationsschritten — oder auch nur ihre Bedeutung.
Die folgende Serie zeigt Schritt für Schritt, wie Ihr einen eigenen Server unter Debian Linux mit Mail, Blog und ein paar anderen nützlichen Dingen aufsetzen könnt. Die Anleitungen sollen sich an Anfänger richten, Ihr dürft Euch nur nicht scheuen, Texte ins Terminalprogramm zu tippen und Konfigurationsdateien zu editieren. Unix-Grundwissen wird nicht vorausgesetzt.
Spätere Kapitel gehen davon aus, dass vorherige Kapitel abgearbeitet worden sind.
Morgen folgt Kapitel 01: „Wir klicken uns einen Server“
Alle Kapitel werden auf dieser Seite verlinkt.
Im ersten Artikel wurde Sparkleshare zwar auf einem Clientrechner eingerichtet, doch interessant ist das natürlich eigentlich erst, wenn man wirklich etwas „sharen“ kann (daher der Name). Wie man das konfiguriert, will ich in diesem Artikel vorführen. Für die folgende Anleitung nehme ich an, dass der Gitolite-Server wie beschrieben eingerichtet und auf jedem teilnehmenden Rechner schon Sparkleshare installiert ist. Die dabei erzeugten öffentlichen ssh-Schlüssel seien alle bereits dort gesammelt, wo das magische gitolite-admin-Repository verwaltet wird (bei mir ist das mein MacBook, eventuell irgendwo auf dem Server, vielleicht direkt in Sparkleshare).
Was wir im folgenden tun werden ist im Endeffekt nur die Konfiguration von Zugriffsrechten auf einem Gitolite-Server.
Dropbox ist toll: auf vielen Systemen unterstützt, einfach zu benutzen, bis zu einem gewissen Volumen kostenlos und irrsinnig zuverlässig.
Aber man vertraut seine Dateien eben doch fremden Leuten an (mit den üblichen Implikationen), und dass die Größe geteilter Ordner jedem Teilnehmer einzeln vom Konto abgezogen wird, ist zumindest schwierig zu verstehen. Google Drive ist ungefähr dasselbe in blau-rot-gelb-blau-grün-rot.
An dieser Stelle tritt Sparkleshare auf den Plan. Damit kann man Ordner über mehrere Rechner (Windows, Mac und Desktop Linux sind im Moment unterstützt) und mit mehreren Personen synchron halten, ohne die Daten bei irgendeiner fremden Firma herumliegen haben zu müssen. Als Speicher fungiert die verteilte Versionsverwaltung git.
Ich will hier mal kurz vorführen, wie man sich das, sofern man einen Rootserver (oder virtuellen Server) mit ssh-Zugang hat, autark aufsetzen kann.
How I Store My 1′s and 0′s: ZFS + Bargain HP Microserver = JOY
»I’m not building one of my kickass web hosting platforms here. It’s for storing those 1′s and 0′s, serving them back up at a reasonable speed and taking reasonable precautions not to lose the data.«
Auf den Merkzettel für den nächsten Heimserver. Wenn Notebooks in Zukunft keine rotierenden Platten mehr haben, dann werde ich nicht mehr alles spazieren tragen können/wollen.
on mocko.org.uk · the article page · mocko.org.uk on QUOTE.fm
Svensonsan bastelt. Irgendwas klappt noch nicht so richtig. Ich habe Hilfe angeboten.
Wir stellen uns also vor, wir hätten ein WordPress (ganz normal, ohne Multisite-Funktion) auf einer Domain im Unterverzeichnis blog liegen. Das soll sich jetzt ändern, das „/blog“ soll aus allen URLs raus, die ganzen existierenden Links und Suchmaschinenergebnisse dürfen dabei aber nicht kaputt gehen. Der folgend beschriebene Weg dürfte der einfachste sein. Er funktioniert aber nur, wenn sich nicht gleichzeitig auch die Permalink-Struktur geändert hat:
Der Anfang liegt in der WordPress-Konfiguration. In der Datenbank oder wp-config.php müssen WP_HOME und WP_SITEURL auf die neue Adresse eingestellt werden. Jetzt funktioniert erstmal nichts mehr.
Als nächstes rücken die Dateien alle um ein Verzeichnis nach oben. Da ist es gut, wenn man Shellzugang zu seinem Webserver hat, denn nur mit ftp wird das beliebig eklig oder zumindest langwierig (abhängig davon, was den Server kann). Also zum Beispiel:
cd /var/www mv htdocs htdocs.old mv htdocs.old/blog htdocs
Jetzt funktionieren die neuen URLs aber die alten nicht mehr (dadurch sind wahrscheinlich auch alle Bilder kaputt etc. etc. — das war beabsichtigt, also keine Sorge). Wir legen deshalb in unserem Rootverzeichnis der Domain (im Beispiel /var/www/htdocs) einen neuen Ordner blog an und lassen Apache die Umschreibarbeit machen. In die Datei blog/.htaccess schreiben wir:
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteBase /
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule ^(.*)$ http://www.example.com/$1 [R=301,L]
</IfModule>
Dadurch werden alle angeforderten Dateien unterhalb von „/blog“ auf dieselbe Adresse ohne „/blog“ umgeleitet. Schon sollte alles wieder funktionieren. Jedenfalls habe ich so den Umzug von WordPress in einem Verzeichnis auf WordPress µ für die ganze Domain geschafft.
(Übung für Fortgeschrittene mit genug Adminrechten: den Ordner blog muss man nicht unbedingt im WordPress-Verzeichnis anlegen, er kann auch durch die Apache-Konfiguration von anderer Stelle eingeblendet werden.)
Die in Teil 1 schon erwähnte Sicherheitsrichtlinie schreibt auch vor, dass VPN-Zugänge logisch nicht an Maschinen sondern nur an Personen gebunden sein dürfen. Bisher hatten wir OpenVPN mit X.509-Zertifikaten zur Zugangsbeschränkung benutzt. Die Zertifikate lassen sich zwar mit einem Passwort verschlüsseln, das kann aber vom Besitzer des Zertifikats leicht geändert werden. Eine echte Zweifaktorauthentifizierung geht anders.
Da trifft es sich gut, dass OpenVPN auch nach Benutzername und Passwort fragen kann. Die können direkt hinterlegt sein, mit einem entsprechenden Plugin kann man aber PAM mitbenutzen:
plugin /usr/lib/openvpn/openvpn-auth-pam.so login
Auf client-Seite muss die bestehende Konfigurationsdatei durch eine Zeile ergänzt werden, damit der Benutzer nach dem übermittelnden Passwort gefragt wird:
auth-user-pass
PAM hatten wir ja in Teil 1 schon an Active Directory angebunden, was wir hier jetzt problemlos mitbenutzen können. Fertig.
Einschränkung: da der OpenVPN-Endpunkt oft ein Rechner ist, auf dem sich die so „entstandenen“ Benutzer gar nicht interaktiv anmelden sollen, empfiehlt sich die Einrichtung einer restricted Shell und die entsprechende Anpassung der smb.conf:
template shell = /bin/rbash template homedir = /home/restricted
(und wenn man schon dabei ist, dann sollte man dort auch alle Services entfernen).
Als wir noch nicht Microsoft-Gold-Partner waren, und uns die Windowslizenzen noch nicht nachgeworfen wurden, wurden hier ein paar Linux-Server als Fileserver aufgebaut. Mit Linux kann man (über NIS und den Automounter) sehr einfach die Benutzerverzeichnisse und -dateien über mehrere Rechner verteilen. Die Windows-Arbeitsplatzrechner hatten zu der Zeit noch keine Anbindung an eine zentrale Benutzerverwaltung sondern lokale Benutzerkonten.
Mit der Einführung von Exchange (statt Lotus Domino) wurde später eine Active Directory-Domäne eingerichtet, so dass Benutzernamen und Passwörter jetzt auf allen Windowsrechnern einheitlich funktionieren. Die Linux-Rechner blieben bisher außen vor (weil wir aber auf dem Fileserver einige Unix-Eigenheiten nutzen, weil es dort eine sehr gute vollautomatische Backupsoftware gibt, und weil außerdem inzwischen auch einige andere Dienste auf den Maschinen laufen kommt eine Umstellung auf Windows nicht ohne weiteres in Betracht).
Diese Gesamtkonstruktion sorgt dafür, dass für jeden Benutzer (mindestens) drei Passwörter existieren (AD, Unix/NIS, Samba). Wenn ein Benutzer nur eins davon ändert, dann wird er an (für ihn) unvorhersehbaren Stellen plötzlich nach einem (welchem?) Passwort gefragt. Die Lösung dafür war bisher einfach: die Benutzer änderten ihre Passwörter nicht (gibt es eigentlich Untersuchungen darüber, ob häufiger Passwortwechsel die Sicherheit eher erhöht oder verringert?). Jetzt sind wir aber seit kurzem mittelbares Tochterunternehmen einer Bank, und die hat einen Katalog an IT-Sicherheitsrichtlinien, zu dem auch eine Mindestkomplexität (8 Zeichen, große und kleine Buchstaben, Zahlen und Sonderzeichen) und eine Höchstgültigkeitsdauer (90 Tage) für Passwörter gehören.
Zeit also für eine Anbindung zwischen Linux und Active Directory:
RT @Morgenland ach ja: #love #linux und #ubuntu … 🙂 #waseinfachmalgesagtgehoert // und #debian #
Hier hatte ich schonmal versucht, mit iptables und dem recent-Modul, die lästigen ssh-Scanner vom tatsächlichen sshd fernzuhalten. Leider hat das nie wirklich toll geklappt (die „Angreifer“ wurden zwar ausgesperrt, es gelang aber nie, die Sperre automatisch aufzuheben).
Nach zwei bis drei erfolgreichen DoS-Attacken auf unser Firmennetz habe ich mir die Liste der iptables-Module nochmal genauer durchgesehen, ob da nicht was passendes dabei ist — und siehe da; das hashlimit-Modul kann eine Regel auf eine Höchstzahl von Treffern pro Zeiteinheit beschränken. Das liest sich dann so:
#
# keep established connections open
#
iptables -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
iptables -A FORWARD -m state --state ESTABLISHED,RELATED -j ACCEPT
#
# enable ssh:
#
# throttle to 2 (3) connections per minute for outsourcing and internet
iptables -N ssh
iptables -A ssh -m hashlimit --hashlimit 2/minute --hashlimit-burst 3 \
--hashlimit-mode srcip --hashlimit-name ssh --j ACCEPT
iptables -A ssh -j LOG --log-level info --log-prefix "SSH scan blocked: "
iptables -A ssh -j REJECT
iptables -A INPUT -p tcp --destination-port 22 --syn -j ssh
iptables -A FORWARD -p tcp --destination-port 22 --syn -j ssh
Das syn-Paket (also der Verbindungsaufbau) wird höchstens zweimal pro Minute durchgelassen, bestehende Verbindungen sind erlaubt. So funktioniert es.
Echte Helden
(Die wunderbare Welt von Isotopp)
[…] Cornelius hat damals jedenfalls die ersten Unix-Kisten eingeschleppt. Natürlich gab es so etwas damals nicht fertig, sonst hätte ihn das wohl auch nicht interessiert. In seinem Fall waren das stattdessen Commodore 900 mit Coherent 0.7.1 Special Binary Prerelease, Prototypen von Rechnern, die Commodore nie gebaut hat, weil sie selbst für Commo zu Scheiße waren. Das war mein erstes Unix. […]
aus Delicious/steinhobelgruen
OpenSCEP
OpenSCEP is an open source implementation of the SCEP protocol used by Cisco routers for certificate enrollment to build VPNs. It implements most of the draft specification, include as reference in the distribution.
aus Delicious/steinhobelgruen
Tux behält den Überblick (und wacht über die Sessionzeiten).
Ich benutze logcheck. Das warnt mich bei ungewöhnlichen Aktivitäten in den Logs der Server. Leider kommt es dabei häufig vor, daß man die eigentlichen Fehler garnicht finden kann, weil man sich durch endlose Wüsten von fehlgeschlagenen ssh-Logins blättern muß:
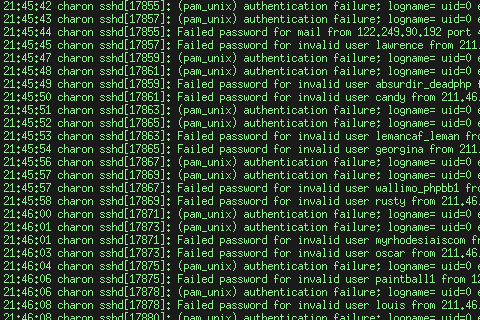
Das nervt. Haben die Scriptkiddies nichts besseres zu tun als Shellaccounts mit schlechten Paßwörtern zu suchen? Nach ein wenig herumsichen bin ich aber hier (wenn auch nicht im Artikel sondern in den Kommentaren) auf eine einfache Lösung gestoßen:
iptables -N ssh iptables -A ssh -m state --state ESTABLISHED -j ACCEPT iptables -A ssh -m recent --update --seconds 300 --hitcount 5 -j REJECT iptables -A ssh -m recent --set -j ACCEPT iptables -A INPUT -p tcp --destination-port 22 -j ssh iptables -A FORWARD -p tcp --destination-port 22 -j ssh
Jetzt kann jeder Client pro 5 Minuten nur noch 5 ssh-Verbindungen öffnen, was in der Regel reichen sollte (man kann das ja auch noch etwas tunen…), danach wird die Verbindung verweigert. Test:
dentaku@charon:~$ ssh trenger@svn.advanced-solutions.de uname -a
Linux kampenwand 2.6.15 #1 SMP Thu Jun 8 18:38:40 CEST 2006 i686 GNU/Linux
dentaku@charon:~$ ssh trenger@svn.advanced-solutions.de uname -a
Linux kampenwand 2.6.15 #1 SMP Thu Jun 8 18:38:40 CEST 2006 i686 GNU/Linux
dentaku@charon:~$ ssh trenger@svn.advanced-solutions.de uname -a
Linux kampenwand 2.6.15 #1 SMP Thu Jun 8 18:38:40 CEST 2006 i686 GNU/Linux
dentaku@charon:~$ ssh trenger@svn.advanced-solutions.de uname -a
Linux kampenwand 2.6.15 #1 SMP Thu Jun 8 18:38:40 CEST 2006 i686 GNU/Linux
dentaku@charon:~$ ssh trenger@svn.advanced-solutions.de uname -a
Linux kampenwand 2.6.15 #1 SMP Thu Jun 8 18:38:40 CEST 2006 i686 GNU/Linux
dentaku@charon:~$ ssh trenger@svn.advanced-solutions.de uname -a
ssh: connect to host svn.advanced-solutions.de port 22: Connection refused
dentaku@charon:~$
Vor Jahren, da lebte ich noch bei meinen Eltern, hatte ich im Keller einen Linux-Server. Das war ein (gebraucht gekaufter) PC mit 486DX2/66-Prozessor und 24MB RAM und VESA-Localbus-Architektur. Da es ein Server war steckte die Grafikkarte trotzdem im ISA-Bus und der VL-Bus war dem SCSI-Hostadapter vorbehalten. Das kleine Ding hatte eine Menge Aufgaben: per ISDN stellte es den Internetzugang (über T-Online) zur Verfügung (das Haus war 10Base2-Verkabelt), diente als HTTP-Cacheproxy (mit Squid 1.1.17) und Fileserver, erledigte den Mail- und Newsverkehr (sendmail 8.8.5), war Anrufbeantworter (vbox) und empfing Faxe (mit einem V.34-Modem). Eine msql-Datenbank mit ein paar cgi-Skripten auf einem Apache (1.1, glaube ich) diente als Liste aller auf Video aufgenommener Filme, außerdem war noch der wegen seiner Lautstärke und des Ozongeruchs in den Keller verbannte Laserdrucker dran angeschlossen…
Einen erheblichen Teil dieser Aufgaben haben heutzutage dieser gemietete Rootserver hier und ein DSL/VoIP/WLAN-Router übernommen, die Fileserver-Aufgabe übernahm aber bisher immer mein Arbeitsplatzrechner so nebenbei. Der blieb deshalb meistens angeschaltet und brauchte viel Strom. Doch damit ist jetzt Schluß:

Dieses kleine Kästchen (ganz links) ist eigentlich eine NAS-„Appliance“ (also ein Einzweckcomputer mit Betriebssystem im Flashspeicher), die sich „Network Storage Link for USB2.0“ (kurz: NSLU2) nennt, und die genau das tut, was der Name sagt. Das Eingebettete Betriebssystem ist aber Linux-basiert und die Architektur offiziel unterstützt, und deshalb kann man stattdessen einfach eine normale Linux-Distribution aufspielen, dann hat man einen kleinen Server mit 266MHz IXP-422-Pozessor und 32MiB RAM (also besser als der alte spartacus). Man nehme also (z.B.) Debian für ARM-Prozessoren und ab da wird’s interessant:
spartacus:~# uname -a Linux spartacus 2.6.18-6-ixp4xx #1 Tue Feb 12 00:57:53 UTC 2008 armv5tel GNU/Linux spartacus:~#
Im Moment laufen schon DHCP- und DNS-Server sowie NFS-Fileserver (mit der großen USB-Platte, die danebensteht — der dritte Kasten ist ein Lautsprecher und hat nichts damit zu tun) drauf. Mal sehen, was der kleine noch alles kann.
![]()
OpenID ist ein SingleSignOn-System (hauptsächlich für webbasierte Dienste), daß eine geniale Lösung für die Probleme bietet, die aus der Abhängigkeit von einer zentralen Stelle entstehen: es arbeitet verteilt. Als Identität braucht man eigentlich nur eine Adresse (in URL-Form), von der aus man auf eine Identität bei einem OpenID-Provider (Identity Provider) verweist. Nur dort meldet man sich noch an, weitere Dienste machen die Anmeldung dann mit dem IdP aus (und auch die Freigabe und Übertragung von Metadaten wie Name, eMail-Adresse und Geburtsdatum).
Da das alles auf einem offenen Protokoll basiert gibt es einen Haufen Identity Provider — und man kann sich auch selbst einen aufsetzen (das habe ich natürlich sofort gemacht…). Und sollte der ausgewählte IdP mal verschwinden (oder unsympatisch werden), dann kann man seine Identität zu einem anderen deligieren.
Das sind genug Gründe um dieses Verfahren zu unterstützen. Ich will deshalb alle Dienste auf wazong.de nach und nach mit einer OpenID-Anmeldung ausrüsten. Die WordPress-Installation für dieses Blog hat jetzt schon das WP-OpenID-Plugin von Will Norris. Wer mit einer OpenID-fähigen URL kommentiert, der kann sich die Eingaben für Name und eMail-Adresse sparen.
Eigenartig ist nur, daß ausgerechnet mein eigener IdP und das WordPress-Plugin noch nicht ordentlich miteinander reden. Da ist noch Debugging angesagt.