Seit der letzten Erwähnung meiner Mastodon-Instanz hat sich noch so einiges getan. Auf der einen Seite sind noch so einige Benutzerkonten dazugekommen (wir sind aktuell so ungefähr bei 230), und auf der anderen Seite habe ich ein paar der letzes mal noch offenen Hausaufgaben gemacht:
Regeln
Ja, die Hausregeln sind inzwischen explizit aufgeschrieben. Erst mit expliziten Regeln ergibt Moderation überhaupt Sinn.
Und ich habe bei der Gelegenheit auch gleich ein git-Repository eingerichtet, das einerseits eine ausführlichere Version der bewusst knapp gehaltenen Regeln enthält und andererseits die Möglichkeit zur Mitarbeit bietet (dazu muss im Moment leider noch ein eigener Account auf meinem git-Server erstellt werden, aber ich setze da große Hoffnung in das forgefed-Projekt).
Monitoring
Ein Dienst, der nicht ordentlich überwacht ist, muss automatisch als offline gelten.
Grafana
Deshalb habe ich zwei Exporter installiert, die Daten über den aktuellen Zustand der Instanz für Prometheus bereitstellen (statsd_exporter und prometheus-mastodon-exporter) und ein Dashboard zur Visualisierung in Grafana gebaut.
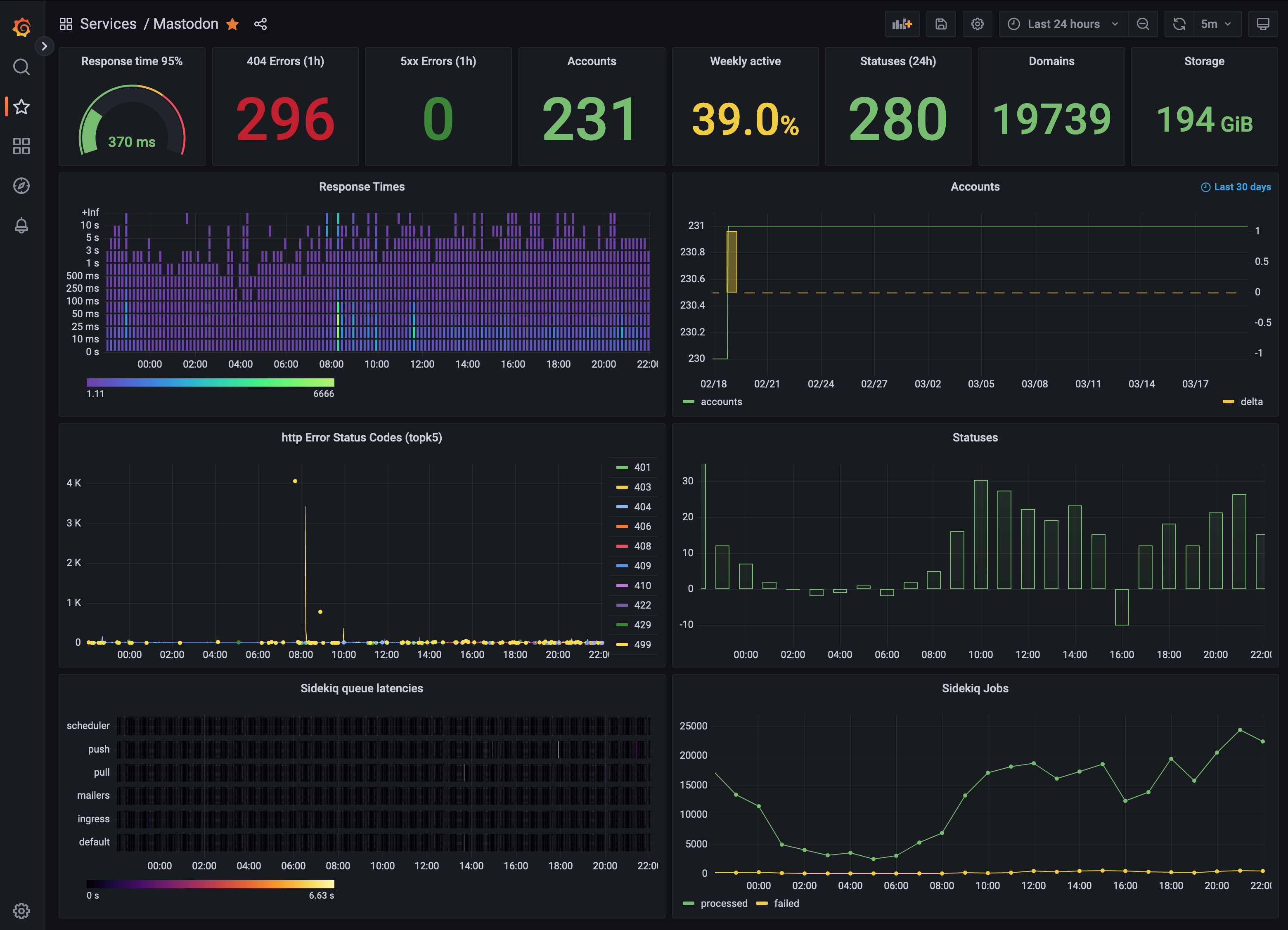
Darauf kann ich jetzt mit einem Blick sehen, ob es meinem Mastodon gerade gut geht, oder ob z.B. die Antwortzeiten ungewöhnlich angestiegen sind oder die Hintergrundprozesse klemmen.
Uptime Kuma
Seit Version 4.1 hat Mastodon außerdem die Möglichkeit gewonnen, den Link zu einer Statusseite zu hinterlegen. Das habe ich zum Anlass genommen, auf einer VM in Helsinki Uptime Kuma zu installieren. Denn fast alle meine Dienste laufen im gleichen Rechenzentrum bei Hetzner in Falkenstein, und sollte das mal komplett nicht erreichbar sein, würde auch mein normales Monitoring nicht mehr funktionieren.

Jetzt bekomme ich auch bei Netzwerkproblemen sofort Benachrichtigungen, und die Fnordon-Benutzer:innen können auch nachsehen, ob es am Dienst oder an ihrem Ende liegt, wenn sie Fnordon nicht erreichen.
MinIO
In Vorbereitung auf den geplanten Umzug aller Dienste auf Kubernetes, und um Mastodon später mal überhaupt in einem über mehrere Maschinen verteilten Cluster betreiben zu können, habe ich schließlich noch die Mediendateien in einen Object Storage ausgelagert. Das klingt nicht nur schick und modern sondern sollte auch die Ladezeiten von Bildern und Videos in Beiträgen und von Avataren erheblich verringern. Mastodon unterstützt Amazon S3 und kompatible Systeme direkt, und MinIO läuft gut in Kubernetes.
Mit diesen Verbesserungen und der aktuellen Anzahl von Accounts dürfte Fnordon weiter locker laufen können, müsste eigentlich sogar etwa für die zehnfache Menge geeignet sein. Wer also noch eine digitale Heimat im Fediverse sucht, kann sich gerne melden.